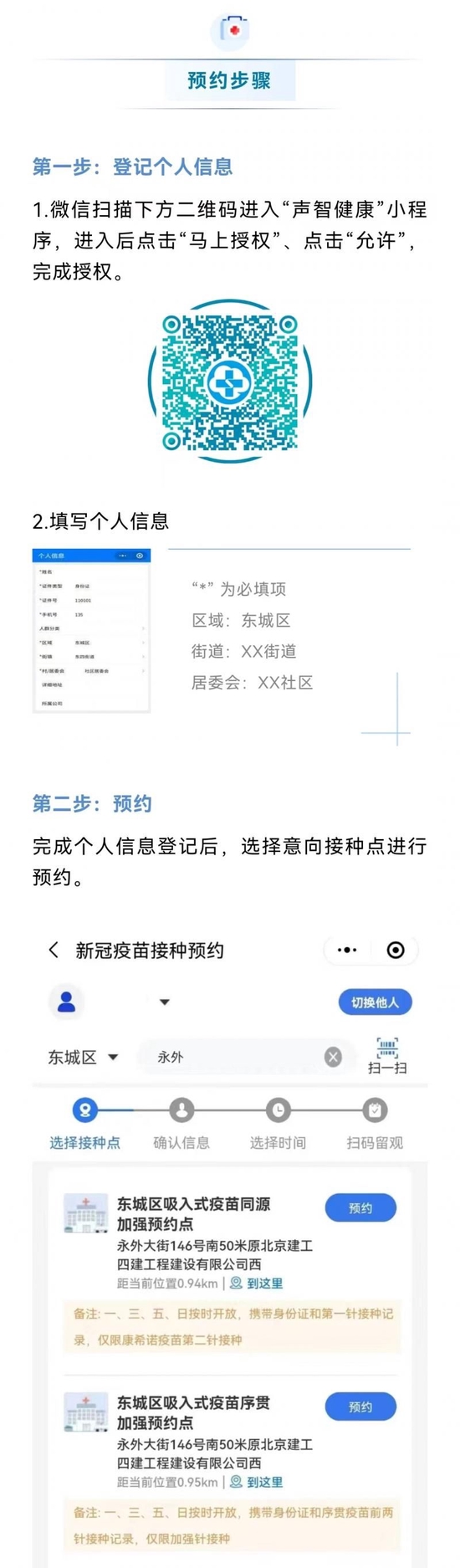
ЕпИВДЋЭГаХЯЂЫбЫїЃЌDeepRetrievalШУФЃаЭЖЫЕНЖЫЕибЇЛсЫбЫїЃЁ
дкаХЯЂМьЫїЯЕЭГжаЃЌЫбЫїв§ЧцЕФФмСІжЛЪЧгАЯьНсЙћЕФвЛИіЗНУцЃЌеце§ЕФЦПОБЭљЭљдкгкЃКгУЛЇЕФдЪМ query БОЩэВЛЙЛКУЁЃ
гШЦфдкзЈвЕЫбЫїГЁОАЃЈШчЮФЯзЁЂЪ§ОнПтВщбЏЃЉжаЃЌгУЛЇЭљЭљЮоЗЈгУОЋШЗЁЂЭъећЕФБэДяУшЪіЫћУЧЕФашЧѓЁЃ
ФЧУДЮЪЬтРДСЫЃКФмВЛФмНЬДѓФЃаЭгХЛЏдЪМ query ЕФБэДяЗНЪНЃЌДгЖјШУвбгаМьЫїЯЕЭГЕФФмСІБЛзюДѓЛЏМЄЗЂЃП
РДзд UIUC ЕФ Jiawei Han КЭ Jimeng Sun ЭХЖгЕФвЛЯюзюаТЙЄзїDeepRetrievalОЭЪЧеыЖдетИіЮЪЬтЬсГіСЫЯЕЭГадНтЗЈЃЌжЛаш3B ЕФ LLMМДПЩЪЕЯж 50 ИіЕувдЩЯЕФЬсЩ§ЁЃ
ТлЮФБъЬтЃКDeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement LearningТлЮФЕижЗЃКhttps://arxiv.org/pdf/2503.00223ПЊдДДњТыЃКhttps://github.com/pat-jj/DeepRetrievalПЊдДФЃаЭЃКhttps://huggingface.co/DeepRetrieval
вЛОфЛАИХРЈЃКDeepRetrieval ЪЧвЛИіЛљгкЧПЛЏбЇЯАЃЈRLЃЉЕФ query гХЛЏЯЕЭГЃЌбЕСЗ LLM дкВЛЭЌМьЫїШЮЮёжагХЛЏдЪМВщбЏЃЌвдзюДѓЛЏецЪЕЯЕЭГЕФМьЫїаЇЙћЁЃ
ЫќВЛЪЧбЕСЗвЛИіаТЕФ retrieverЃЌвВВЛЪЧШУФЃаЭжБНгЛиД№ЮЪЬтЃЌЖјЪЧЃК
дкВЛИФБфЯжгаЫбЫїЯЕЭГЕФЧАЬсЯТЃЌЭЈЙ§гХЛЏдЪМ queryЃЌШУЁИЬсЮЪЗНЪНЁЙБфЕУИќДЯУїЃЌДгЖјЛёШЁИќКУЕФНсЙћЁЃ
ИќЖргавтвхЕФЬжТлЧыЖСдЮФе§ЮФКЭИНТМЕФ Discussion ВПЗжЁЃ
ЗНЗЈЯИНк
ЗНЗЈвЊЕу
ЪфШыЃКдЪМВщбЏ qЪфГіЃКИФаДКѓЕФВщбЏ qЁфЃЈздШЛгябдЁЂВМЖћБэДяЪНЛђ SQLЃЉЛЗОГЗДРЁЃКЪЙгУ qЁф ШЅМьЫїЯЕЭГжаВщбЏ Ёњ ЗЕЛиНсЙћ Ёњ гы groundtruth ЖдБШЃЌМЦЫу rewardЃЌreward ЮЊ task-specific МьЫїБэЯжЃЈШч Recall@KЁЂNDCG@KЁЂSQL accuracyЃЉЪЙгУ PPO НјаабЕСЗЃЌВЂМгШыИёЪННБРјЃЈformat correctnessЃЉгы KL-regularization БЃжЄбЕСЗЮШЖЈЃЌгХЛЏФПБъШчЯТЃК
ЦфжаЃЌІа_ref ЪЧВЮПМВпТдЃЈreference policyЃЉЃЌЭЈГЃжИЕФЪЧдкЧПЛЏбЇЯАПЊЪМжЎЧАЕФГѕЪМФЃаЭЁЃІТ ЪЧвЛИіКЯЪЪЕФ KL ГЭЗЃЯЕЪ§ЃЌгУгкПижЦе§дђЛЏЕФЧПЖШЁЃKL ЩЂЖШЯюЕФзїгУЪЧГЭЗЃЕБЧАВпТдгыВЮПМВпТджЎМфЕФЙ§ДѓЦЋРыЃЌДгЖјдкЧПЛЏбЇЯАбЕСЗЙ§ГЬжаБЃжЄВпТдИќаТЕФЮШЖЈадЁЃ
ЪЕбщНсЙћ
ецЪЕЫбЫїв§ЧцЕФЮФЯзЫбЫї
ЪзЯШдкецЪЕЕФЫбЫїв§ЧцЩЯНјааЪЕбщЃЌЮФжагУЕНСЫзЈвЕЫбЫїв§Чц PubMed КЭ ClinicalTrials.govЁЃЮоашИФЖЏЫбЫїв§ЧцЛђЦфЫќШЮКЮМьЫїЦїЃЌНіЭЈЙ§ЖЫЕНЖЫЕигХЛЏ query БэДяЃЌDeepRetrieval ОЭПЩвдШУНсЙћЛёЕУ 10 БЖЬсЩ§ЃЌдЖГЌИїИіЩЬвЕДѓФЃаЭКЭжЎЧАЕФ SOTA ЗНЗЈ LEADSЃЈеєСѓ + SFT ЗНЗЈЃЉЁЃ
Evidence-Seeking МьЫїЃКЭЈгУЫбЫїв§ЧцЕФИяаТЧБСІ
DeepRetrieval дк Evidence-Seeking МьЫїШЮЮёЩЯЕФгХвьБэЯжСюШЫжѕФПЁЃШчБэ 1 ЫљЪОЃЌНсКЯМђЕЅ BM25ЃЌетИіНіга 3B ВЮЪ§ЕФФЃаЭдк SQuADЁЂTriviaQA КЭ NQ Ъ§ОнМЏЩЯГЌдНСЫ GPT-4o КЭ Claude-3.5 ЕШДѓаЭЩЬвЕФЃаЭЁЃ
Evidence-Seeking ШЮЮёЕФКЫаФЪЧевЕНжЇГжЬиЖЈЪТЪЕадЮЪЬтД№АИЕФШЗЧаЮФЕЕжЄОнЃЌдкЭЈгУЫбЫїв§ЧцЛЗОГжаЃЌетвЛФмСІгШЮЊЙиМќЁЃзїепЭХЖгжИГіЃЌНЋ DeepRetrieval гІгУЕН GoogleЁЂBing ЕШЭЈгУЫбЫїв§ЧцЕФ Evidence-Seeking ГЁОАНЋДјРДЯджјгХЪЦЃК
ОЋзМЖЈЮЛЪТЪЕЮФЕЕЃКЭЈгУЫбЫїв§ЧцАќКЌКЃСПаХЯЂЃЌгУЛЇФбвдЙЙНЈФмОЋШЗЖЈЮЛжЄОнЖЮТфЕФВщбЏЁЃDeepRetrieval ПЩНЋМђЕЅЮЪЬтзЊЛЏЮЊАќКЌЙиМќЪѕгяЁЂЭЌвхДЪКЭЯоЖЈЗћЕФИДдгВщбЏЃЌЯджјЬсИпевЕНШЈЭўжЄОнЕФИХТЪЁЃПЫЗўжЊЪЖЪБаЇадЯожЦЃКФЃаЭФмЙЛНЋЁИ2024 ФъАТдЫЛсН№ХЦАёЧАШ§УћЁЙЕШГЌГі LLM жЊЪЖНижЙШеЦкЕФЮЪЬтзЊЛЏЮЊОЋШЗЫбЫїБэДяЃЌЪЙМьЫїЯЕЭГФмЙЛевЕНзюаТЪТЪЕжЄОнЁЃЖрдДбщжЄФмСІЃКЭЈЙ§гХЛЏВщбЏАяжњЫбЫїв§ЧцевЕНЖрИіЖРСЂРДдДЕФЪТЪЕжЄОнЃЌДгЖјНЛВцбщжЄаХЯЂзМШЗадЃЌетЪЧДП LLM ЮЪД№ЮоЗЈЪЕЯжЕФЙиМќгХЪЦЁЃ
зїепЭХЖгБэЪОЛсНЋетВПЗжЕФбгЩьзїЮЊ DeepRetrievalЮДРДжївЊЕФЬНЫїЗНЯђжЎвЛ
Classic IRЃЈSparse / DenseЃЉ
дк BM25 КЭ dense retriever ЯТЃЌDeepRetrieval ЬсЙЉСЫЦНОљ 5~10 Еу NDCG ЬсЩ§ЃЌВЂЧвЃКBM25 + DeepRetrieval КЭЖрЪ§ dense baseline ЫЎЦНЯрЕБЁЃ
НсКЯМЋПьЕФМьЫїЫйЖШЃЈBM25 vs denseЃК352s vs 12,232sЃЉЃЌеЙЪОСЫвЛИіЯжЪЕПЩВПЪ№ЁЂадФмВЛЫзЕФИпаЇЗНАИЁЃ
SQL МьЫїШЮЮё
дк SQL МьЫїШЮЮёжаЃЌDeepRetrieval АкЭбСЫЖд groundtruth SQL ЕФвРРЕЃЌжБНгРћгУЩњГЩ SQL ЕФжДааГЩЙІТЪгХЛЏФЃаЭЃЌЭЈЙ§ЩњГЩИќОЋзМЕФ SQL гяОфЃЌЪЙЕУФЃаЭдк SpiderЁЂBIRD ЕШЪ§ОнМЏЩЯЕФжДаае§ШЗТЪОљГЌЙ§ЖдБШФЃаЭЃЈАќРЈ GPT-4o КЭЛљгк SFT ЕФДѓФЃаЭЃЉЁЃ
ЬНЫїЪЄгкФЃЗТЃКRL ЮЊКЮГЌдН SFT
DeepRetrieval ЕФЪЕбщНвЪОСЫЧПЛЏбЇЯАЃЈRLЃЉдкЫбЫїгХЛЏЩЯЯрБШМрЖНЮЂЕїЃЈSFTЃЉЕФЖРЬигХЪЦЁЃЪЕбщЪ§ОнСюШЫаХЗўЃКдкЮФЯзЫбЫїЩЯЃЌRL ЗНЗЈЕФ DeepRetrievalЃЈ65.07%ЃЉГЌЙ§ SFT ЗНЗЈ LEADSЃЈ24.68%ЃЉНќШ§БЖЃЛдк SQL ШЮЮёЩЯЃЌДгСуПЊЪМЕФ RL бЕСЗЃЈЮоашШЮКЮ gold SQL гяОфЕФМрЖНЃЉвВгХгкЪЙгУ GPT-4o еєСѓЪ§ОнЕФ SFT ФЃаЭЁЃ
етжжЯджјВювьдДгкСНжжЗНЗЈЕФБОжЪЧјБ№ЃКSFT ЪЧЁИФЃЗТбЇЯАЁЙЃЌЪдЭМИДжЦВЮПМВщбЏЃЌЖј RL ЪЧЁИжБНггХЛЏЁЙЃЌЭЈЙ§ЛЗОГЗДРЁбЇЯАзюгХВщбЏВпТдЁЃSFT ЗНЗЈЕФОжЯодкгкВЮПМВщбЏБОЩэПЩФмВЛЪЧзюгХЕФЃЌМДЪЙЪЧШЫРрзЈМвЛђДѓФЃаЭвВФбвджБЙлЩшМЦГізюЪЪКЯЬиЖЈЫбЫїв§ЧцЕФВщбЏБэДяЁЃ
ТлЮФжаЕФАИР§ЗжЮіНјвЛВНжЄЪЕСЫетвЛЕуЁЃР§ШчЃЌдк PubMed ЫбЫїжаЃЌDeepRetrieval ЩњГЩЕФВщбЏШчЁИ((DDAVP) AND (Perioperative Procedures OR Blood Transfusion OR Desmopressin OR Anticoagulant)) AND (Randomized Controlled Trial)ЁЙШкКЯСЫвНбЇСьгђЕФзЈвЕЪѕгяКЭ PubMed ЫбЫїв§ЧцЦЋКУЕФВМЖћНсЙЙЃЌетжжзщКЯКмФбЭЈЙ§МђЕЅФЃЗТдЄЖЈвхЕФВщбЏФЃАхЛёЕУЁЃ
ЯрЗДЃЌRL дЪаэФЃаЭЭЈЙ§ГЂЪдгыДэЮѓРДЬНЫїВщбЏПеМфЃЌЗЂЯжШЫРрЩѕжСЮДПМТЧЕФгааЇФЃЪНЃЌВЂжБНгеыЖдзюжеФПБъЃЈШч Recall ЛђжДаазМШЗТЪЃЉНјаагХЛЏЁЃетЪЙ DeepRetrieval ФмЙЛЩњГЩИпЖШЪЪКЯЬиЖЈЫбЫїв§ЧцЬиадЕФВщбЏЃЌЪЪгІВЛЭЌМьЫїЛЗОГЕФЖРЬиашЧѓЁЃ
етвЛЗЂЯжОпгаживЊЦєЪОЃКдкзЗЧѓзюМбМьЫїадФмЪБЃЌШУФЃаЭЭЈЙ§ЗДРЁбЇЯАШчКЮгыМьЫїЯЕЭГЁИЖдЛАЁЙЃЌБШМђЕЅФЃЗТМШЖЈФЃЪНИќЮЊгааЇЃЌетвВНтЪЭСЫЮЊКЮВЮЪ§СПНЯаЁЕФ DeepRetrieval ФмдкЖрЯюШЮЮёЩЯГЌдНгЕгаИќЖрВЮЪ§ЕФЩЬвЕФЃаЭЁЃ
ФЃаЭ Think&Query ГЄЖШЗжЮі
ЭЈЙ§ЗжЮі DeepRetrieval дкбЕСЗЙ§ГЬжаФЃаЭЫМПМСДКЭВщбЏГЄЖШЕФБфЛЏЃЌПЩвдЗЂЯжвдЯТЙиМќЖДМћ
ЫМПМСДГЄЖШбнБф
гыЁИaha momentЁЙЯрЗДЃЌDeepRetrieval ЕФЫМПМСДГЄЖШЫцбЕСЗГЪЯТНЕЧїЪЦЃЌЖјЗЧдіГЄЁЃетгы DeepSeek-R1 БЈИцЕФЁИaha momentЁЙЯжЯѓаЮГЩЯЪУїЖдБШЃЌКѓепЕФЫМПМСДЛсЫцбЕСЗНјеЙБфЕУИќГЄЁЃЭМ 4(a) ЧхЮњЕиеЙЪОСЫ Qwen ФЃаЭЫМПМСДДгГѕЪМдМ 150 tokens ж№НЅНЕжСЮШЖЈЕФ 50 tokens зѓгвЃЌЖј Llama ФЃаЭЕФЫМПМСДИќЖЬЃЌЩѕжСНЕжСНгНќ 25 tokensЁЃ
ВщбЏГЄЖШЬиеї
ЪЕбщНвЪОСЫЫМПМЙ§ГЬЖдВщбЏГЄЖШЕФЯджјгАЯьЁЃЮоЫМПМЙ§ГЬЕФФЃаЭШнвзЯнШыДЮгХНтЃЌШчЭМ 4(b) ЫљЪОЃЌQwen ЮоЫМПМАцБОЩњГЩМЋГЄВщбЏЃЈ500-600 tokensЃЉЃЌБэЯжГіЙ§ЖШРЉеЙЕФЧуЯђЁЃЯрБШжЎЯТЃЌгаЫМПМЙ§ГЬЕФФЃаЭБЃГжИќЮЊЪЪжаЕФВщбЏГЄЖШЃЌQwen дМ 150 tokensЃЌLlama дМ 100 tokensЁЃгаШЄЕФЪЧЃЌВЛЭЌФЃаЭВЩгУВЛЭЌГЄЖШВпТдЃЌЕЋФмДяЕНЯрЫЦадФмЃЌБэУїВщбЏЩњГЩДцдкЖрбљгааЇТЗОЖЁЃ
адФмгыЫМПМЙ§ГЬЙиЯЕ
ЫМПМЙ§ГЬЖдМьЫїадФмгаОіЖЈадгАЯьЁЃЭМ 4(c) БэУїЃЌОпБИЫМПМФмСІЕФФЃаЭадФмЯджјЬсЩ§ЃЌгаЫМПМЕФФЃаЭ Recall@3K ФмДяЕН 65%ЃЌЖјЮоЫМПМФЃаЭНі 50% зѓгвЁЃДЫЭтЃЌбЕСЗаЇТЪвВУїЯдЬсИпЃЌгаЫМПМЕФФЃаЭИќПьДяЕНИпадФмВЂБЃГжЮШЖЈЁЃТлЮФИНТМ D.1 ЕФЗжЮіБэУїЃЌЫМПМЙ§ГЬАяжњФЃаЭБмУтМђЕЅЕиЭЈЙ§діМгВщбЏГЄЖШКЭжиИДЪѕгяРДЬсЩ§адФмЃЌЖјЪЧв§ЕМФЃаЭбЇЯАИќгааЇЕФгявхзщжЏВпТдЁЃ
ЙиМќНсТл
DeepRetrieval еЙЪОСЫЫМПМЙ§ГЬдкаХЯЂМьЫїжаАчбнЁИЬНЫїДйНјЦїЁЙЕФЙиМќНЧЩЋЁЃгыЪ§бЇЛђБрГЬЮЪЬтВЛЭЌЃЌМьЫїШЮЮёВЛашвЊЯёЁИaha momentЁЙФЧбљЕФЭЛШЛЖйЮђЯжЯѓЁЃЯрЗДЃЌМьЫїгХЛЏзёбЁИЯШЯъЯИЫМПМЃЌКѓж№НЅОЋМђЁЙЕФФЃЪНЃЌФЃаЭдкФкЛЏгааЇВпТдКѓЃЌВЛдйашвЊШпГЄЫМПМЁЃетБэУїМьЫїШЮЮёжаЫМПМСДЕФжївЊЙІФмЪЧЬНЫїЃЌвЛЕЉВпТдЮШЖЈБуПЩМђЛЏЁЃ
етжжЗжЮіБэУїЃЌЪЪЕБЕФЫМПМЙ§ГЬЩшМЦЖдгкЙЙНЈИпаЇЕФМьЫїгХЛЏЯЕЭГжСЙиживЊЃЌФмЙЛдкВЛдіМгФЃаЭВЮЪ§ЕФЧщПіЯТЯджјЬсЩ§адФмЃЌЮЊЮДРДЕФ LLM гІгУгкЫбЫїШЮЮёЬсЙЉСЫживЊЩшМЦЫМТЗЁЃ
НсТл
DeepRetrieval ЕФЙБЯздкгкНвЪОСЫвЛИіГЃБЛКіЪгЕЋжСЙиживЊЕФЪТЪЕЃКМьЫїаЇЙћЕФЩЯЯоВЛНідкгкМьЫїЦїБОЩэЃЌИќдкгкШчКЮЁИЬсЮЪЁЙЁЃ
ЭЈЙ§ЧПЛЏбЇЯАНЬ LLM ИФаДдЪМВщбЏЃЌDeepRetrieval ВЛНіАкЭбСЫЖдШЫЙЄБъзЂЪ§ОнКЭДѓФЃаЭеєСѓЕФвРРЕЃЌЛЙдкЖрИіШЮЮёЩЯжЄУїСЫИФаД query ЕФОоДѓЧБСІЁЃетЯюЙЄзїЮЊЫбЫїгыаХЯЂМьЫїСьгђДјРДСЫаТЕФЫМПМЃКЮДРДЕФМьЫїгХЛЏЃЌВЛНіЪЧЬсЩ§в§ЧцЫуЗЈЃЌИќЪЧШчКЮШУгУЛЇЁИЮЪЕУИќКУЁЙЃЌДгЖјМЄЗЂГіМьЫїЯЕЭГЕФШЋВПЧБСІЁЃ
ЯрЙиЭЦМіЃК成人18禁秘啪啪免费 真人实景女处被破www免费看 大乳老师办公室❌❌❌大乳游戏
美女裸身㊙️免费
男性脱👙给我揉🐻+亲嘴动漫
美女裸体❌开腿出内裤下载网站
国产熟妇码AV水也
裸体❌开腿❌狂喷游戏
纯肉小黄文高H短篇
国产精品㊙️18禁拍拍音频
三级小说肥水不流外人田性欲很强大的留守肥婆
成人Hオンライン动漫
中国少妇被黑人XXOO
日本极限扩大拳交
云缨疯狂喷水自慰
韩国裸体㊙️无遮挡热舞
羞羞漫在线观看♥无限免费
原神同人18禁
不知火舞❌到满身奶水漫画软件
班长❌开腿让我爽小说
斯嘉丽裸被✘到喷水
男男3D猛交XXXX免费看
做爱视频免费不失效
朴妮唛三级露全乳视频
nxgx100%2023款
看裸体🔞🔞🔞网站阳水
老熟妇久久爽爽成人
冰公主张开腿让颜爵揉双乳
梅花十三去掉内裤让人摸
星野4月26号录屏回放免费高清版
红桃视频18🈲
毛笔挠尿孔~啊快尿了
小sao贷大ji巴cao死你
国产清纯女学生被弄高潮小说
曼珠沙华裸体图同人
色欲AV精品亚洲AV高清茉莉
用力⋯哦⋯高潮⋯喷水
18🈲小泬破白浆啪啪免费软件
成人污污www网站免费丝瓜
furry老虎猛交大肉自慰
扒开女人👙给男生摸🍑视频
总裁穿丁字裤夹震蛋器出门小说
被粗大的🐔巴捣出白浆动漫
女同被c🔞黄㊙️❌游戏
国产精品㊙️久久桃子冰
心海被❌18禁动漫黄网站
原神涩涩同人3D❌18禁水神
千仞雪3D㊙️让男人桶爽
尼亚州AZ秘一区二区三
无尽裸体扶她动漫
老师′胸乳❌❌❌视频软件
妲己乳液乱飙🚺👙网站
黄鳝门琪琪3分26秒无代码
跪趴夹震蛋器到高潮H流好多牛奶
打针+被绑+虐菊+虐乳+折磨小说
91丨国产丨白浆㊙️冰块动漫
憋尿连体衣
熟妇馒头黑肥骚B
怮交小拗女视频观看
国产❌❌❌18🈲㊙️照片
男男暴菊GAYXXXcom
美女扒开胸罩㊙️露出奶头偷东西
亚洲女同一区 二区三区
八戒八戒电影在线观看动画
五条悟被C得合不拢腿
能设姐姐脚上吗
熊猫yy8y官网
久久久精品人妻一区亚美
裸体初音被❌到爽动漫
fc2ppv绝美SSS级素人
欧美❌❌B❤BBB
delicate霉霉
操女人骚逼,淫乱网站
MM131杨晨晨被❌
国产色情性黄片Av网站
cekc高清BNДeo❌❌
《好好疼爱里面》动漫在线看
被绑到刑床强扒开腿狂虐的视频
女坐隐私㊙️黄www网站视频
亚洲人做受❌❌❌高潮日本望乡
男科医院刺激偷拍取精过程
爽⋯好大⋯快⋯深一点美女被折
莱欧斯利的裸体㊙️网站
おはようございます的四个特征
ЭјгбЦРТл ВщПДЫљгаЦРТл>>